Basic Knowledge for linux kernel pwn
前置知识
系统调用
系统调用表
所有的系统调用被声明于内核源码
arch/x86/entry/syscalls/syscall_64.tbl中,在该表中声明了系统调用的标号、类型、名称、内核态函数名称在内核中使用【系统调用表】
System Call Table对系统调用进行索引,该表中储存了不同标号的系统调用函数的地址
进入系统调用
Linux 下进入系统调用有两种主要的方式:
32位:执行
int 0x80汇编指令(80号中断)64位:执行
syscall汇编指令 / 执行sysenter汇编指令(only intel)
Linux 由用户态进入到内核态的流程
Linux下的系统调用以
eax/rax寄存器作为系统调用号,参数传递约束如下:32 位:
ebx、ecx、edx、esi、edi、ebp作为第一个参数、第二个参数…进行参数传递64 位:
rdi、rsi、rdx、rcx、r8、r9作为第一个参数、第二个参数…进行参数传递
退出系统调用
内核执行完系统调用后退出系统调用也有对应的两种方式:
执行
iret汇编指令执行
sysret汇编指令 / 执行sysexit汇编指令(only Intel)
进程管理
在内核中使用结构体
task_struct表示一个进程,该结构体定义于内核源码include/linux/sched.h中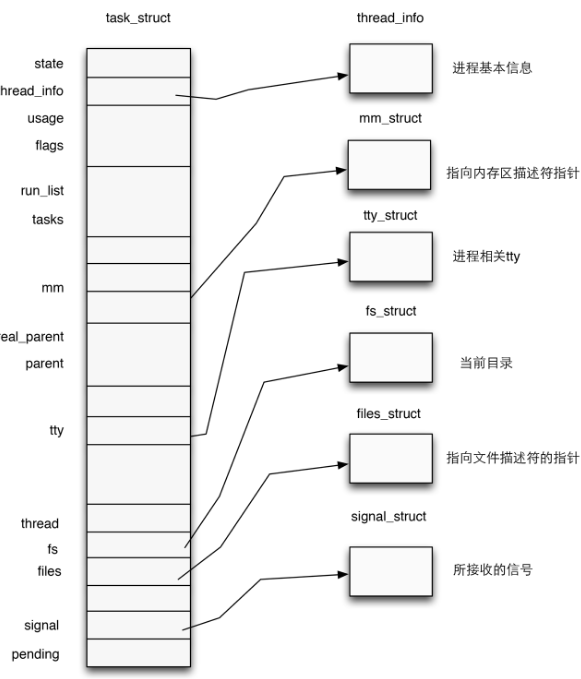
关于进程权限管理部分(注释部分更改了)
Process credentials 是 kernel 用以判断一个进程权限的凭证,在 kernel 中使用
cred结构体进行标识,对于一个进程而言应当有三个 cred:ptracer_cred:使用
ptrace系统调用跟踪该进程的上级进程的cred(gdb调试便是使用了这个系统调用,常见的反调试机制的原理便是提前占用了这个位置)real_cred:即客体凭证(objective cred),通常是一个进程最初启动时所具有的权限
cred:即主体凭证(subjective cred),该进程的有效cred,kernel以此作为进程权限的凭证
当进程 A 向进程 B 发送消息时,A为主体,B为客体
1
2
3
4
5
6
7->Process credentials:
--> Tracer's credentials at attach:
const struct cred __rcu *ptracer_cred;
--> Objective and real subjective task credentials (COW):
const struct cred __rcu *real_cred;
--> Effective (overridable) subjective task credentials (COW):
const struct cred __rcu *cred;
进程权限凭证 struct : cred
对于一个进程,在内核当中使用一个结构体
cred管理其权限,该结构体定义于内核源码include/linux/cred.h中
1 | struct cred { |
一个cred结构体中记载了一个进程四种不同的用户ID:
- 真实用户ID(real UID):标识一个进程启动时的用户ID
- 保存用户ID(saved UID):标识一个进程最初的有效用户ID
- 有效用户ID(effective UID):标识一个进程正在运行时所属的用户ID,一个进程在运行途中是可以改变自己所属用户的,因而权限机制也是通过有效用户ID进行认证的,内核通过 euid 来进行特权判断;为了防止用户一直使用高权限,当任务完成之后,euid 会与 suid 进行交换,恢复进程的有效权限
- 文件系统用户ID(UID for VFS ops):标识一个进程创建文件时进行标识的用户ID
进程权限改变
- 只要改变一个进程的
cred结构体,就能改变其执行权限 - 在内核空间有如下两个函数,都位于
kernel/cred.c中:struct cred* prepare_kernel_cred(struct task_struct* daemon):该函数用以拷贝一个进程的cred结构体,并返回一个新的cred结构体,需要注意的是daemon参数应为有效的进程描述符地址或NULLint commit_creds(struct cred *new):该函数用以将一个新的cred结构体应用到进程
提权
关于函数
prepare_kernel_cred注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/**
* prepare_kernel_cred - Prepare a set of credentials[凭据] for a kernel service
* @daemon: A userspace daemon to be used as a reference
*
* Prepare a set of credentials for a kernel service. This can then be used to
* override a task's own credentials so that work can be done on behalf of that
* task that requires a different subjective context.
*
* @daemon is used to provide a base for the security record, but can be NULL. <-----!!!
* If @daemon is supplied, then the security data will be derived from that;
* otherwise they'll be set to 0 and no groups, full capabilities and no keys.
*
* The caller may change these controls afterwards if desired.
*
* Returns the new credentials or NULL if out of memory.
*
* Does not take, and does not return holding current->cred_replace_mutex.
*/声明
cred.h1
extern struct cred *prepare_kernel_cred(struct task_struct *);
定义
cred.c1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
struct cred *prepare_kernel_cred(struct task_struct *daemon)
{
const struct cred *old;
struct cred *new;
new = kmem_cache_alloc(cred_jar, GFP_KERNEL);
if (!new)
return NULL;
kdebug("prepare_kernel_cred() alloc %p", new);
if (daemon)
old = get_task_cred(daemon);
else
old = get_cred(&init_cred); <-- if daemon is null
...
在
prepare_kernel_cred()函数中,若传入的参数为NULL,则会缺省使用init进程的cred作为模板进行拷贝,【即可以直接获得一个标识着root权限的cred结构体】(这是由于init进程是root权限的)关于
init1
2
3
4init (the first process forked by kernel in OS)
* pid : 1 --> 进程id
* gid : 1 --> 进程组id
* sid : 1 --> 会话idinit_cred的声明位置:linux-5.4.98/include/linux/init_task.h1
extern struct cred init_cred;
定义位置:
linux-5.4.98/kernel/cred.c1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/*
* The initial credentials for the initial task
*/
struct cred init_cred = {
.usage = ATOMIC_INIT(4),
.subscribers = ATOMIC_INIT(2),
.magic = CRED_MAGIC,
.uid = GLOBAL_ROOT_UID,
.gid = GLOBAL_ROOT_GID,
.suid = GLOBAL_ROOT_UID,
.sgid = GLOBAL_ROOT_GID,
.euid = GLOBAL_ROOT_UID,
.egid = GLOBAL_ROOT_GID,
.fsuid = GLOBAL_ROOT_UID,
.fsgid = GLOBAL_ROOT_GID,
.securebits = SECUREBITS_DEFAULT,
.cap_inheritable = CAP_EMPTY_SET,
.cap_permitted = CAP_FULL_SET,
.cap_effective = CAP_FULL_SET,
.cap_bset = CAP_FULL_SET,
.user = INIT_USER,
.user_ns = &init_user_ns,
.group_info = &init_groups,
};
I/O
一切皆文件
- 在Linux系统的视角下,无论是文件、设备、管道,还是目录、进程,甚至是磁盘、套接字等等,一切都可以被抽象为文件,一切都可以使用访问文件的方式进行操作通过这样一种哲学,Linux予开发者以高层次抽象的统一性,提供了
操作的一致性:- 所有的读取操作都可以通过read进行
- 所有的更改操作都可以通过write进行
进程文件系统
- 进程文件系统(
process file system, 简写为procfs)用以描述一个进程,其中包括该进程所打开的文件描述符、堆栈内存布局、环境变量等等- 进程文件系统本身是一个【伪文件系统】,通常被挂载到
/proc目录下,并不真正占用储存空间,而是占用一定的内存 - 当一个进程被建立起来时,其进程文件系统便会被挂载到
/proc/[PID]下,我们可以在该目录下查看其相关信息
- 进程文件系统本身是一个【伪文件系统】,通常被挂载到
文件描述符
进程通过文件描述符(file descriptor)来完成对文件的访问,其在形式上是一个非负整数,本质上是对文件的索引值,进程所有执行 I/O 操作的系统调用都会通过文件描述符
每个进程都独立有着一个文件描述符表,存放着该进程所打开的文件索引,每当进程成功打开一个现有文件/创建一个新文件时(通过系统调用open进行操作),内核会向进程返回一个文件描述符
在kernel中有着一个文件表,由所有的进程共享
stdin、stdout、stderr
每个
*NIX进程都应当有着三个标准的POSIX文件描述符,对应着三个标准文件流:stdin 标准输入 0 stdout 标准输出 1 stderr 标准错误 2 【此后打开的文件描述符应当从标号
3起始】!!!
syscall: ioctl
在
*NIX中一切都可以被视为文件,因而一切都可以以访问文件的方式进行操作,为了方便,Linux定义了系统调用ioctl供进程与设备之间进行通信
系统调用ioctl是一个专用于设备输入输出操作的一个系统调用,其调用方式如下:
1 | int ioctl(int fd, unsigned long request, ...) |
- fd:设备的文件描述符
- request:请求码
- 其他参数
对于一个提供了ioctl通信方式的设备而言,我们可以通过其文件描述符fd、使用不同的请求码及其他请求参数通过ioctl系统调用完成不同的对设备的I/O操作
例如CD-ROM驱动程序弹出光驱的这一操作就对应着对“光驱设备”这一文件通过ioctl传递特定的请求码与请求参数完成
LKMs
Loadable Kernel Modules(LKMs):- Linux Kernle采用的是宏内核架构,一切的系统服务都需要由内核来提供,虽然效率较高,但是:
- 缺乏可扩展性与可维护性
- 内核需要装载很多可能用到的服务,但这些服务最终可能未必会用到,还会占据大量内存空间
- 新服务的提供往往意味着要重新编译整个内核
- 综合以上考虑,可装载内核模块
Loadable Kernel Modules,简称LKMs,出现了,位于内核空间的LKMs可以提供新的系统调用或其他服务, - LKMs可以像积木一样被装载入内核/从内核中卸载,大大提高了kernel的可拓展性与可维护性
- Linux Kernle采用的是宏内核架构,一切的系统服务都需要由内核来提供,虽然效率较高,但是:
- 常见的外设驱动便是LKM的一种
- LKMs与用户态可执行文件一样都采用ELF格式,但是LKMs运行在内核空间,且无法脱离内核运行
- 通常与LKM相关的命令有以下三个:
lsmod:列出现有的LKMsinsmod:装载新的LKM(需要root)rmmod:从内核中移除LKM(需要root)
保护机制
KASLR
内核内存布局参考:多版本kernel内核内存布局
- KASLR即【内核空间地址随机化(
kernel address space layout randomize)】,与用户态程序的ASLR相类似——在内核镜像映射到实际的地址空间时加上一个偏移值,但是内核内部的相对偏移其实还是不变的 - 在未开启KASLR保护机制时,内核的基址为
0xffffffff81000000
FGKASLR
KASLR 虽然在一定程度上能够缓解攻击,但是若是攻击者通过一些信息泄露漏洞获取到内核中的某个地址,仍能够直接得知内核加载地址偏移从而得知整个内核地址布局
- 因此有研究者基于 KASLR 实现了 FGKASLR,以函数粒度重新排布内核代码
Stack Protector
类似于用户态程序的
canary,通常又被称作是stack cookie,用以检测是否发生内核堆栈溢出,若是发生内核堆栈溢出则会产生kernel panic
- 内核中的
canary的值通常取自gs段寄存器某个固定偏移处的值
SMAP/SMEP
- SMAP:管理模式【访问】保护(
Supervisor Mode Access Prevention) - SMEP:管理模式【执行】保护(
Supervisor Mode Execution Prevention) - 这两种保护通常是同时开启的,用以阻止内核空间直接访问/执行用户空间的数据,完全地将内核空间与用户空间相分隔开,用以防范
ret2usr(return-to-user,将内核空间的指令指针重定向至用户空间上构造好的提权代码)攻击 - SMEP保护的绕过有以下两种方式:
- 在设计中,为了使隔离的数据进行交换时具有更高的性能,隐性地址共享始终存在(VDSO & VSYSCALL),用户态进程与内核共享同一块物理内存,因此通过隐性内存共享可以完整的绕过软件和硬件的隔离保护,这种攻击方式被称之为
ret2dir(return-to-direct-mapped memory ) - Intel下系统根据CR4控制寄存器的第20位标识是否开启SMEP保护(1为开启,0为关闭),若是能够通过kernel ROP改变CR4寄存器的值便能够关闭SMEP保护,完成SMEP-bypass,接下来就能够重新进行
ret2usr
- 在设计中,为了使隔离的数据进行交换时具有更高的性能,隐性地址共享始终存在(VDSO & VSYSCALL),用户态进程与内核共享同一块物理内存,因此通过隐性内存共享可以完整的绕过软件和硬件的隔离保护,这种攻击方式被称之为
KPTI
KPTI即
内核页表隔离(Kernel page-table isolation),内核空间与用户空间分别使用两组不同的页表集,这对于内核的内存管理产生了根本性的变化
- KPTI 机制的出现使得 ret2usr 彻底成为过去式